ETSimilarityPro函数,根据文本相似性进行排序。数据排序的基本逻辑为,相同的字符越多,两个文本越相似,不同的文本越多,两个文本差异越大。
同时考虑字符的权重,如果文本在序列文本内出现次数越多,则这个文本权重越小。如果某个词在文本之中出现的次数越少,则该字符的权重越大。
基于上述两个规则,对序列内文本进行排序,函数结果为多行一列数组数据。
该函数通常应用于数据预处理场合。
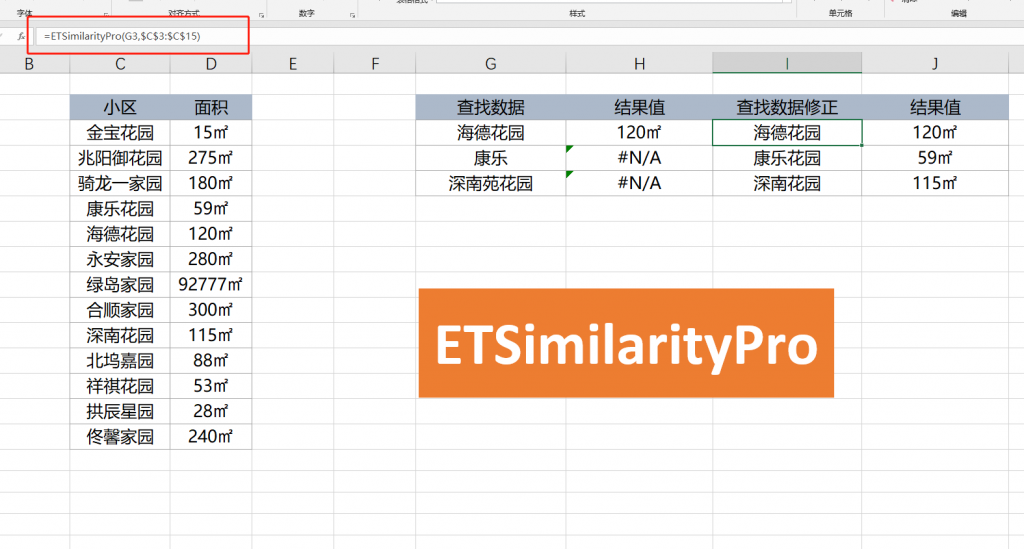
例如下图案例,因为数据录入不规范,同一个主体被描述为两个不同的文字。如果直接通过VLOOKUP函数,不能够查找出来结果是多少。
这时可以使用ETSimilarityPro函数。使用该函数,将文本数据进行修正。先查找出来待查找数据在列表内实际文本。获得实际文本后,就可以利用VLOOKUP函数提取结果信息了。
这里需要注意ETSimilarityPro函数结果为近似结果,需要进一步确认该文本是否是实际需要的数值。